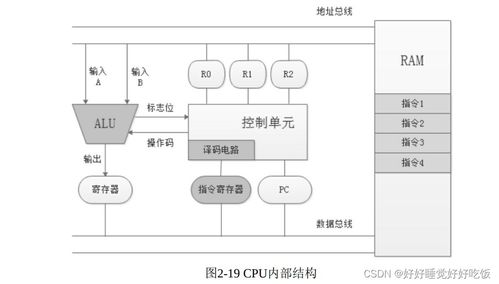
計算機的發展歷程可分為四個主要階段:第一,電子管時代(20世紀40-50年代),計算機體積龐大、功耗高,以ENIAC為代表,主要用于科學計算;第二,晶體管時代(20世紀50-60年代),計算機體積縮小、可靠性提高,開始應用于商業領域;第三,集成電路時代(20世紀60-70年代),隨著集成電路的出現,計算機性能大幅提升,操作系統逐步成熟;第四,大規模和超大規模集成電路時代(20世紀70年代至今),計算機微型化、智能化,個人電腦和互聯網普及,人工智能技術蓬勃發展。
計算機系統集成是指將各個獨立的計算機硬件、軟件、網絡等組件整合為一個協調高效的整體系統。它涵蓋需求分析、方案設計、設備選型、系統實施及維護等環節,旨在實現資源共享、功能優化和業務協同。例如,企業通過系統集成將服務器、數據庫和應用程序結合,構建統一的信息管理平臺。隨著云計算和物聯網技術的發展,系統集成更注重靈活性、可擴展性和安全性,成為推動數字化轉型的關鍵支撐。